


我们迄今为止最智能、功能最强大的模型,具有全部工具访问权限。
今日,我们正式发布 OpenAI o3 和 o4-mini,这是我们 o 系列模型的最新成员,该系列模型经过训练,能够在回应之前进行更深入的思考。这两款模型是我们迄今为止发布的最为智能的模型,无论是好奇的普通用户还是资深的研究人员,所有人都能从中感受到 ChatGPT 能力的显著提升。我们的推理模型首次能够自主调用并整合 ChatGPT 内的所有工具,包括网络搜索、利用 Python 分析上传的文件和其他数据、对视觉输入进行深度推理,甚至生成图像。尤为关键的是,这些模型经过训练,能够判断何时以及如何使用工具,以恰当的输出格式提供详尽且经过思考的回答(通常在一分钟内),从而解决更为复杂的问题。这使得它们能够更有效地处理涉及多个层面的问题,朝着能够独立代表用户执行任务的更具自主性的 ChatGPT 迈进了一步。前沿的推理能力与全面的工具调用的结合,使模型在学术基准测试和实际任务中的表现大幅提升,在智能性和实用性方面树立了新的标杆。
新模型有哪些变化
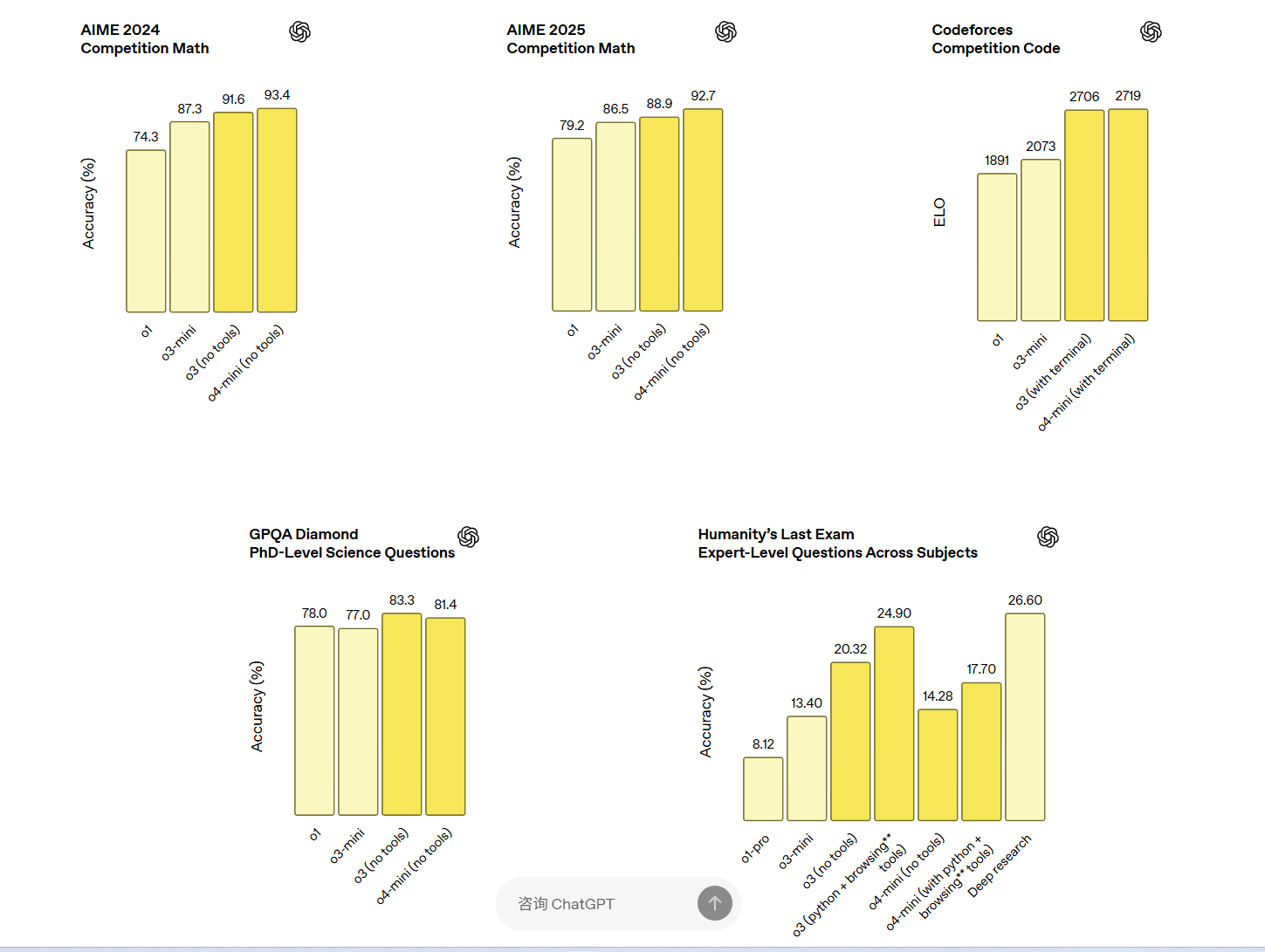
OpenAI o3 是我们功能最为强大的推理模型,在编码、数学、科学、视觉感知等多个领域均实现了突破。它在 Codeforces、SWE-bench(无需构建定制化的特定模型框架)和 MMMU 等基准测试中均取得了新的最优成绩。该模型非常适合处理需要多维度分析且答案并非显而易见的复杂问题。在视觉任务方面,如分析图像、图表和图形,o3 表现尤为出色。在外部专家的评估中,面对高难度的现实任务,o3 比 OpenAI o1 的重大错误率降低了 20%,尤其在编程、商业/咨询和创意构思等领域表现超群。早期测试者特别指出 o3 作为思考伙伴的分析严谨性,以及其生成和批判性评估新假设的能力,特别是在生物学、数学和工程领域。
OpenAI o4-mini 是一款更小型但经过优化的模型,旨在实现快速且经济高效的推理。尽管其规模较小、成本较低,但在数学、编码和视觉任务等方面均拥有卓越的性能。在 AIME 2024 和 2025 的基准测试中,它的表现最为出色。虽然使用计算机可以显著降低 AIME 考试的难度,但我们发现,在 AIME 2025 考试中,当允许 o4-mini 调用 Python 解译器时,其取得了 99.5% pass@1(首次尝试即通过的比例)、100% consensus@8(8 次尝试中的共识正确率)的成绩。虽然这些结果不应与无法调用工具的模型性能直接比较,但凸显出 o4-mini 利用工具的效率;在 AIME 2025 考试中,允许调用工具的 o3 的表现也有类似提升 (98.4% pass@1, 100% consensus@8)。
在专家评估中,o4-mini 在非 STEM 任务以及数据科学等领域也超越了其前身 o3‑mini。得益于其高效率,o4-mini 的使用限制远高于 o3,非常适合用于解决需要推理支持的问题,尤其是高体量、高吞吐量的场景。外部专家评估者认为,这两款模型在指令遵循方面表现出色,提供的回答比其前身更有用、更可验证,这得益于其智能性的提升以及网络资源的整合。与之前的推理模型版本相比,这两款模型的使用体验也更加自然、对话感更强,尤其是它们能够参考记忆和过往对话,使回答更加个性化、更贴合需求。
持续扩展强化学习
在开发 OpenAI o3 的过程中,我们观察到大规模强化学习展现出了与 GPT 系列预训练相同的“计算量增加 = 性能提升”的趋势。通过追溯这一扩展路径 — 这次是在强化学习领域 — 我们在训练计算量和推理时推理方面均提高了一个数量级,并且仍然看到了明显的性能提升,这表明模型的性能确实会随着思考时间的增加而持续提高。在保持与 OpenAI o1 相同的延迟和成本的情况下,o3 在 ChatGPT 中展现出了更高的性能,并且我们已经验证,如果允许 o3 进行更长时间的思考,其性能还将持续提升。
此外,我们还通过强化学习训练这两个模型使用工具 — 不仅教它们如何使用工具,还教它们判断何时使用工具。它们能够根据期望的结果来部署工具,这使得它们在开放式场景中更加得心应手,特别是在涉及视觉推理和多步骤工作流程的情况下。根据早期测试者的反馈,这种改进在学术基准测试和实际任务中均有所体现。